
Raspberry Pi RP2040 (Teil 2): PIO-Programmierung am Beispiel eines Laserscanner-Interface
Im ersten Teil der Miniserie zum Raspberry Pi RP2040 im MATHEMA Blog habe ich den RP2040 und insbesondere seine programmierbaren I/Os bewertet. Diese PIOs sind innovativ und können eine Lücke zwischen reinen Microcontrollern und FPGAs füllen.
In diesem Teil geht es darum, auf dem Raspberry Pico mit Hilfe einer PIO eine bisher nicht unterstützte Schnittstelle zu implementieren, um ihre Möglichkeiten auszuloten.
Vorsicht: In diesem Artikel wird es technisch und ich werde das Programm in seiner vollen Länge von 24 Befehlen eingehend erklären. ![]()
Zuvor aber eine kurze Darstellung dieser Schnittstelle und nochmal eine Zusammenfassung der Programmierung der PIOs.
Das XY2-100 Laserscanner-Interface
Das XY2-100 Interface ist ein Interface für Laserscanner, wie sie in der Industrie zum Beschriften von Produkten verwendet werden, z.B. für ein Mindesthaltbarkeitsdatum oder eine fortlaufende Artikelnummer. Diese Schnittstelle ist für diesen Anwendungszweck sehr verbreitet, findet sich aber auf praktisch keinem Microcontroller. Deshalb war bisher meist ein FPGA notwendig.
Über das XY2-100 Interface wird einem X/Y-Scankopf 100.000-mal pro Sekunde eine neue Position übermittelt - daher der Name. Es gibt auch eine Version mit doppeltem Takt - das XY2-200 Interface - und Geräte mit 3 Koordinaten. Auch die lassen sich mit dem RP2040 darstellen. Der doppelte Takt ist problemlos möglich und für eine dritte Koordinate benutzt man die noch freie vierte State Machine. Bei anderen Varianten, z.B. mit 18 statt 16 Datenbits und mit Befehlen im Datenstrom, muss der Pico wahrscheinlich passen.
Das XY2-100 Interface besteht aus 4 differenziellen Leitungspaaren für CLOCK, SYNC, X-DATA und Y-DATA. Die Datenworte sind 20 Bit lang und beginnen mit der Bitfolge '001', gefolgt von der 16-Bit Position für den Scanner (MSB first) und einem Parity-Bit. Während dem Parity-Bit wird die SYNC-Leitung auf 0 gesetzt, sonst ist sie immer 1.

Die PIOs - kurze Wiederholung
Die PIOs werden über ihre State Machines programmiert: Es gibt 2 PIO-Blöcke mit je 4 State Machines und knapp bemessenen 32 Worten Programmspeicher pro Block.
Der Befehlssatz ist mit insgesamt 9 Befehlen spartanisch. Dafür werden alle Befehle in nur einem Takt und mit bis zu 125 MHz abgearbeitet.
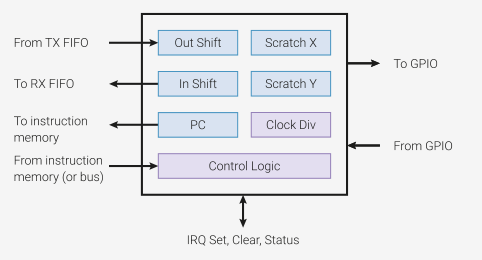
Jede State Machine verfügt über 2 "universelle" Register, dazu je ein Shift Register samt Fifo mit jeweils 4 Worten für IN und OUT, oder eine einzige Fifo mit 8 Worten, wenn nur eine Datenrichtung benötigt wird - wie in unserem Fall.
Die State Machines eines PIO-Blocks können über Statusbits untereinander kommunizieren und sich so synchronisieren oder Interrupts auslösen.
Die Befehle können auf alle GPIO-Pins zugreifen, diese aber zumeist nicht explizit adressieren. Stattdessen werden die State Machines bei der Initialisierung auf GPIO-Bereiche gemappt. Dadurch kann z.B. das gleiche Programm von mehreren State Machines abgearbeitet werden, die jeweils nur anderen Port-Pins zugewiesen sind, wie wir es für X- und Y-Data machen werden. Pro State Machine gibt es 4 solche Mappings für die Befehle IN, OUT, SET, (der Befehl MOV übernimmt je nach Quelle oder Ziel das Mapping für IN oder OUT) und für Side-Set (s.u.). Die Befehle haben zumeist eine implizite Quelle, Ziel oder Datenbreite. Die anderen Angaben werden über Bit-Felder ausgewählt. Die implizite Datenbreite ist entweder die beim Mapping eingestellte oder das Maximum von 32 Bit, z.B. bei IN oder beim Kopieren von Registern mit MOV.
Es gibt insgesamt 9 Befehle:
- JMP [condition] destination
Als Condition sind ausgewählte Vergleiche des X- und Y-Registers möglich, Abfrage eines dedizierten IO-Pins oder Füllstand des Output Shift Registers OSR. - WAIT condition
Als Condition sind ein GPIO-Pin direkt oder mit Pin-Mapping (s.u.) oder ein PIO-IRQ-Flag (Statusbit, s.o.) vorgesehen. - IN liest Bits von den per Pin-Mapping eingestellen IO-Ports oder ein Register in's Input Shift Register ISR.
- OUT schreibt Bits zu den per Pin-Mapping eingestellten IO-Ports, deren Richtungsbits oder ein Register. Der Program Counter PC ist als Ziel auch möglich, was einem Sprung entspricht, oder das Command Register, wodurch das Wort im nächsten Takt als Befehl ausgeführt wird.
- PUSH schreibt das Input Shift Register ISR in die Empfangs-Fifo. PUSH kann bedingt sein ('if ISR full'), blockierend solange die FIFO voll ist oder blindlings auch in eine eventuell volle FIFO hinein.
- PULL liest liest Daten aus der Sende-Fifo in das Output Shift Register OSR. Auch PULL kann conditional sein (if empty), blockierend oder 'blind'.
- MOV kopiert Daten von einer Quelle zu einem Ziel. Beides können IO-Pins mit Pin-Mapping oder ein Register sein. Als Ziel ist auch wieder der PC (Sprung) und EXEC (beliebiger Opcode) möglich. Als Quelle ist eine per State Machine konfigurierbare Bedingung, z.B. der Füllstand einer Fifo möglich. Der MOV-Befehl arbeitet immer mit der maximal möglichen Datenbreite.
- IRQ setzt oder löscht ein PIO-IRQ-Flag (Statusbit), auf das eine andere State Machine vermutlich wartet.
- SET schließlich kopiert einen 5-Bit-Wert in das X- oder Y-Register, auf Out-Pins oder deren Richtungsbits und benutzt hierfür ein eigenes, von MOV und OUT abweichendes Pin-Mapping.
Jeder der Befehle kann 3 Sachen gleichzeitig machen:
- Den eigentlichen Befehl ausführen
- über Side-Set bis zu 5 Pins ändern oder deren Richtung umschalten (je nach Konfiguration der State Machine)
- und bis zu 31 Wartetakte anhängen.
Ein PIO-Assemblerbefehl sieht dann beispielsweise so aus:
mov pins, x side 0b01 [2]
- 'mov pins, x' ist der eigentliche Befehl (kopiere Register X zu den GPIO Pins lt. OUT-Mapping),
- 'side 0b01' setzt 2 GPIOs laut Side-Set-Mapping und
- '[2]' definiert 2 Wartetakte.
Die beiden "Nebeneffekte" Side-Set und Wartetakte werden über die gleichen 5 Bit in jedem Befehl gesteuert und die Zuordnung wird für jede State Machine fest programmiert. Man kann z.B. 2 Bit für Side-Set vorsehen, dann bleiben noch 3 Bit für bis zu 7 Wartetakte in jedem Befehl. Man kann die Side-Set Bits für eine State Machine auch optional machen, dann wird eins der 5 Bit für diese Option benötigt und die restlichen 4 können dann entweder nur für Wartetakte oder für Side-Set plus Wartetakte verwendet werden, je nachdem was günstiger ist.
Der lange Weg zum PIO-Programm
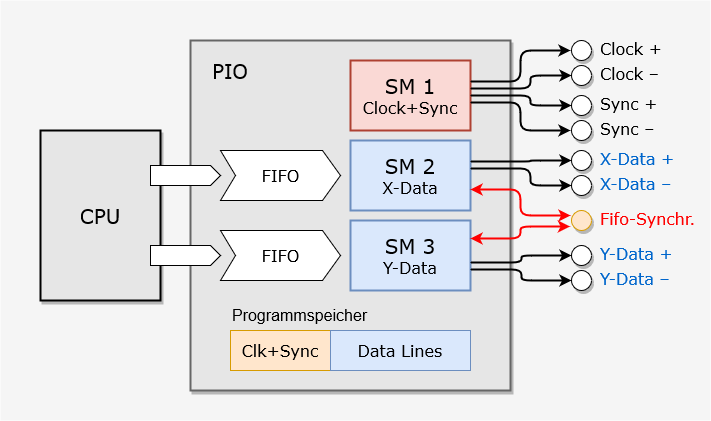
Die hier vorgestellte Implementierung der XY2-100 Schnittstelle benutzt 3 State Machines einer PIO, die zwei unterschiedliche Programme abarbeiten: Eins für Clock und Sync und ein Programm für die beiden Datenleitungen. Die State Machines können sehr einfach synchronisiert werden, indem sie einfach gleichzeitig gestartet werden. Vorausgesetzt man hat sich beim Taktzyklen zählen nicht verzählt, werden sie für immer synchron laufen.
Während die Programmierung des immer gleichen Clock- und Sync-Signals recht einfach ist, bieten die beiden Datenkanäle der XY2-Schnittstelle einige Herausforderungen:
Zunächst einmal muss zu jedem Datenwort ein Parity-Bit berechnet werden. Da die Arithmetik-Möglichkeiten sehr begrenzt sind, habe ich mich schnell für eine Speicherung "im Programmfluss" entschieden: Je nachdem, ob die Parität gerade ungerade/Odd oder gerade/Even ist, wird ein anderer Programmzweig benutzt. Das führt dazu, dass die Schleife über die Datenbits effektiv doppelt vorhanden ist. Es wäre wahrscheinlich auch möglich, das X- oder Y-Register mit 0 zu laden und bei jedem gesetzten Datenbit zu komplementieren. Dann wird weniger Code gedoppelt, der einzelne Codepfad enthält aber mehr Befehle. Das führt vielleicht dazu, dass wir mit den verfügbaren Befehlen pro Takt nicht mehr auskommen und den Takt erhöhen müssten – was natürlich noch ginge, da unsere Lösung bisher nur 4 Takte pro Bit benötigt und somit mit 8 MHz läuft – von maximal möglichen 125 MHz. – Wie immer gibt es natürlich noch viele andere Wege zum Ziel.
Ich wollte alle 8 Leitungen für die 4 komplementären Leitungspaare direkt vom Pico aus ansteuern, um die negativen Signale nicht noch extern invertieren zu müssen bevor ich sie über einen 8-Bit Bustreiber mit 5 Volt zum Scanner sende. Hierfür habe ich einen 74HCT254 verwendet, da die Eingangsschwelle für HCT gut zum 3.3V CMOS-Ausgangssignal des RP2040 passt. Das bedeutet aber, dass ich die Datenbits nicht einfach aus dem Sendeschieberegister auf einen Port-Pin rausschieben kann, was ich wegen der Parity-Berechnung sowieso nicht könnte. Stattdessen wird das Bit in eines der Universalregister geschoben, getestet und dann verzweigt, um entsprechend '01' oder '10' auf die Port-Pins für das Leitungspaar auszugeben.
Hier haben wir dann noch die Wahl, ob wir das mit SET oder mit Side-Set machen: Das Clock-und-Sync-Programm benutzt SET, für die Datenleitungen benutze ich aber Side-Set, weil das parallel zur Programmflusslogik ausgeführt wird, und so Zeit und Platz spart. Für die genaue Synchronisierung der 3 State Machines muss man dabei beachten, dass Side-Set schon am Anfang eines Befehls wirkt, SET aber erst am Ende, also praktisch einen Takt später.
Die Wahl von Side-Set erwies sich noch aus einem anderen Grund als hilfreich: Sie hat eine eigene Pin-Zuordnung und machte so die Zuordnung für IN und OUT frei. Dazu gleich mehr.
Der Programmablauf für einen Datenkanal sieht jetzt wie folgt aus:
Während die drei Header-Bits '001' ausgegeben werden, liest die State Machine das nächste Datenwort aus der Sende-FIFO ins Sendeschieberegister, was sogar automatisch geschehen kann. Sie hat also viel Zeit die sie ab-'wartet'. Die Register der PIO sind 32 Bit breit. Unsere 16 Datenbits müssen MSB first gesendet werden, die oberen 16 Bit sind also zu viel – die werfen wir deshalb gleich weg. Die verbleibenden 16 Datenbits werden nacheinander aus dem Schieberegister gelesen, entsprechend verzweigt und mit Side-Set ausgegeben. Zuletzt wird das Parity-Bit ausgegeben, wodurch unsere Hauptschleife zwei Enden hat. Das macht den Einsatz von '.wrap' unmöglich, was uns sonst den Befehl für den Schleifen-Rücksprung gespart hätte. Für die Ausgabe des Parity-Bits mittels Side-Set benötigen wir an dieser Stelle aber sowieso einen Befehl, in den es als Nebeneffekt hineinkodiert wird.
Soweit so gut und das klappt auch wunderbar, ...
bis die FIFOs mal keine Daten enthalten.
Für diesen Fall kann man einstellen, dass das Schieberegister aus dem X-Register nachgeladen wird. Es ist in diesem Fall sinnvoll, den zuletzt ausgegebenen Wert zu wiederholen. Deshalb kopieren wir den aktuellen Wert jeweils auch in das X-Register, bevor wir ihn ausgeben.
Problem gelöst ...
solange die FIFOs immer gleichzeitig leer laufen. Tun sie aber nicht, weil die CPU sie nur nacheinander beschreiben kann. In einer Race-Condition kann also ein Kanal bereits neue Daten vorfinden während der andere seinen letzten Punkt noch einmal wiederholt. In diesem Fall sollten aber beide Kanäle ihren letzten Punkt wiederholen. Ein Informationsaustausch zwischen den State Machines ist aber nur begrenzt möglich, weil sie jeweils eigene Registersätze haben und die der anderen nicht sehen.
Eine Möglichkeit wäre, nicht 2 State Machines sondern nur eine gemeinsam für X und Y zu benutzen. Dann müsste die CPU die beiden 16-Bit-Koordinaten als ein 32-Bit-Wort in eine einzelne FIFO schreiben. Dadurch wird das Programm für die State Machine aber sehr kompliziert: Zunächst kommt sie an die oberen 16 Bit des 2. Datenwortes gar nicht so einfach heran und die Parity-Berechnung würde den Programmfluss jetzt nicht nur verdoppeln sondern sogar vervierfachen.
Die PIO bietet mit WAIT und IRQ die Möglichkeit, mehrere State Machines zu synchronisieren. Dadurch werden aber Wartetakte eingefügt und das ist das Letzte, was wir jetzt brauchen. Die Synchronisierung mit Clock+Sync, die nur durch penibles Zählen der Takte pro Befehl erreicht wurde, wäre dahin.
Jetzt wird es eng:
Finden wir keine Lösung für das Problem, müssen wir zumindest kurzzeitig eine Abweichung um einen Frame, also um 1/100.000 Sekunde bzw. 10µs zwischen den Kanälen tolerieren und auf der CPU-Seite die FIFOs entsprechend handhaben, oder die PIO-Lösung ist gestorben.
Die PIOs bieten aber noch einige oft unerwartete Möglichkeiten, die, richtig kombiniert, auch dieses Problem lösen :-)
- Der Füllgrad einer FIFO kann von der State Machine in ein Register ausgelesen werden: Die State Machine kann also aktiv mit einer Verzweigung im Programmfluss darauf reagieren. Sonst kann sie die FIFO nur automatisch nachfüllen lassen, oder mit
PULL'blind' in das Schieberegister laden, hat dann aber keine Information darüber, ob Daten drin waren. - Ein Register, und damit der wie oben ermittelte Fifo-Status, kann mit
MOVauf die GPIO-Pins ausgegeben werden.MOVbenutzt dabei das OUT-Pin-Mapping, undOUTbenutzen wir bisher nicht, weil wir Side-Set verwenden. Damit können wir den Fifo-Status mitMOVauf einen 'Synchronisierungs-'' Pin ausgeben. - Wenn mehrere State Machines einen Port-Pin gleichzeitig setzen, 'gewinnt' die State Machine mit der höheren Nummer. Wir können jetzt vereinbaren, dass die FIFO für Y-DATA von der CPU immer zuletzt befüllt wird und die State Machine für Y-DATA die höhere Nummer haben muss und – voilà – gibt dieser Pin den Zustand derjenigen FIFO aus, die später gefüllt wird und in einer Race Condition diejenige ist, die noch keine Daten enthält.
Diesen Zustand müssen wir nun wieder einlesen und entsprechend im Programm verzweigen und das Sende-Shiftregister manuell aus der FIFO oder eben aus dem X-Register nachladen. Dafür können wir auch wieder MOV verwenden, weil wir auch das IN-Mapping noch nicht verwendet haben.
Dazu müssen für OUT und IN nicht einmal zwei unterschiedliche Pins benutzt werden, die man außerhalb des Chips verbindet, man kann auch den Zustand des OUT-Pins selbst lesen.
Was leider nicht geht, ist dafür einen der nicht herausgeführten GPIOs zu benutzen: die wurden beim Design des RP2040 soweit wegoptimiert, dass jetzt 'seltsame Sachen' passieren, wenn man das versucht.
Es kommt aber noch zu einem letzten Problem:
Der MOV-Befehl, mit dem man den Pin wieder einlesen könnte, hat zwar Bits für Quelle und Ziel, aber keine Bits zur Kodierung der Datenbreite. Diese wird von der Programmierung des PINCTRL Registers bestimmt. Dieses enthält in Bitfeldern Start und Länge für OUT, SET und SIDESET, aber nur den Start für IN. Mit MOV und Quelle=PINS und Ziel=Register werden deshalb alle 32 Port-Bits gelesen – wir können das Zielregister danach aber nur als Ganzes testen.
Deshalb wird das Bit stattdessen mit IN in das bisher auch noch nicht benutzte Input-Schieberegister geladen, weil wir hier die Anzahl der zu lesenden Bits angeben können. Danach kopieren wir das Shiftregister ins Y-Register um es testen zu können, um dann endlich entsprechend zu verzweigen und das Output-Schieberegister aus der richtigen Quelle nachzufüllen.
Fazit
Es wäre schwer gewesen, vor einer realen Implementierung vorherzusagen, ob das XY2-100 Interface mit einer RP2040 PIO darstellbar ist. Das hätte auch anders ausgehen können. Im Gegensatz dazu kann man bei einem FPGA ab einer bestimmten Größe sicher davon ausgehen, dass das möglich ist. Der Entwicklungsaufwand dort, wenn man nicht einen fertigen Funktionsblob verwendet, ist aber ebenfalls nicht zu unterschätzen.
Das C++-Programm
Jetzt aber endlich zur Implementierung. Die Source-Dateien sind im Anhang noch einmal verlinkt, die beiden PIO-Programme werden hier aber komplett gelistet und dann abschnittsweise erklärt.
Initialisierung von PIO und State Machines
Der PIO-Assembler erstellt beim Compilieren des Projektes eine Header-Datei, die in das C oder C++ Programm eingebunden werden muss. Sie enthält unsere PIO-Programme in Form von static const Arrays und einige #defines für Label und Konstanten, die in den PIO-Programmen als "public" deklariert wurden.
Das C++-Programm initialisiert eine PIO und darin 3 State Machines für Clock+Sync, X-Data und Y-Data, startet diese synchron und zeichnet dann eine langsam rotierende Lissajous-Figur. Beim Klick auf das untenstehende Bild öffnet sich dazu ein kurzes Video:
-->https://www.youtube.com/watch?v=hZ327MhepIE
Die Initialisierung der PIO umfasst die Zuweisung der GPIO-Pins, was verwirrenderweise mit Hilfe einer State Machine geschieht, und das Laden der PIO-Programme.
Zur Initialisierung der State Machines gehört das Einstellen der Clock, das Laden der Programmstartadresse und das Mapping von GPIO-Pins für IN, OUT, SET und Side-Set, soweit verwendet. Die Konfiguration von wrap und der Side-Set-Bits geschieht schon in der erzeugten Header-Datei. Für die State Machines der Datenleitungen wird auch noch Breite und Schieberichtung des Output-Schieberegisters festgelegt und eingestellt, dass 'MOV STATUS' den Status der Output-Fifo liest. Außerdem wird die unbenutzte Input-Fifo der Output-Fifo zugeschlagen.
Das PIO-Programm für CLOCK und SYNC ist relativ einfach
Es erzeugt das CLOCK-Signal mit 2 MHz für eine Datenrate von 100kHz und in jedem 20. Takt einen Impuls auf der SYNC-Leitung.

.program XY2_100_clock .define public sm_clock 8000000 .define CLOCK_HIGH 0b01 ; pin N = 1, pin N+1 = !1 .define CLOCK_LOW 0b10 ; pin N = 0, Pin N+1 = !0 .define SYNC_HIGH 0b0100 .define SYNC_LOW 0b1000 public start: .wrap_target set x, 18 ; => 19 loops bit_loop: set pins, (SYNC_HIGH + CLOCK_HIGH) [1] set pins, (SYNC_HIGH + CLOCK_LOW) jmp x-- bit_loop set pins, (SYNC_LOW + CLOCK_HIGH) [1] ; parity bit set pins, (SYNC_LOW + CLOCK_LOW) .wrap
Schritt für Schritt:
.program XY2_100_clock
Jedes Pio-Programm beginnt mit einer .program Deklaration und einem Namen, der in der erzeugten Header-Datei in die diversen #defines für dieses Programm eingebaut wird.
.define public sm_clock 8000000
Definition der Clock für die State Machine.
.define definiert eine Konstante. Kommt an zweiter Stelle das Schlüsselwort public, wird sie, erweitert um den Programmnamen, auch als #define in die generierte Headerdatei exportiert, in diesem Fall also als #define XY2_100_clock_sm_clock. Im C++-Programm wird es dann benutzt, um die Clock der State Machine zu konfigurieren.
.define CLOCK_HIGH 0b01 ; pin N = 1, pin N+1 = !1.define CLOCK_LOW 0b10 ; pin N = 0, Pin N+1 = !0.define SYNC_HIGH 0b0100.define SYNC_LOW 0b1000
Convenience-Definition der Bitmuster, mit denen die differenziellen Leitungspaare auf '0' oder '1' gesetzt werden.
public start:
Definition des Programm-Startpunktes:
Das wird als #define XY2_100_clock_offset_start exportiert und im C++-Programm zur Konfiguration der State Machine verwendet.
.wrap_target
Das Programm benutzt 'wrap' für seine äußere Schleife. Das ist eine weitere Besonderheit der RP2040 PIOs, die den sonst nötigen Rücksprung am Ende einer Schleife einsparen kann. Da die State Machines üblicherweise ein Programm unendlich oft wiederholen, spart das nicht nur einen Befehl sondern auch einen Takt, was entscheidend sein kann.
![]() Man kann sich das Programm wie auf einer Walze vorstellen: eigentlich hat sie gar keinen Anfang und kein Ende, sie ist nur gezwungenermaßen irgendwo aufgeschnitten. Hier wird sie wieder mit '.wrap' und '.wrap_target' zusammengeklebt, ohne einen Befehl und somit auch einen Taktzyklus einzufügen.
Man kann sich das Programm wie auf einer Walze vorstellen: eigentlich hat sie gar keinen Anfang und kein Ende, sie ist nur gezwungenermaßen irgendwo aufgeschnitten. Hier wird sie wieder mit '.wrap' und '.wrap_target' zusammengeklebt, ohne einen Befehl und somit auch einen Taktzyklus einzufügen.
set x, 18bit_loop:set pins, (SYNC_HIGH + CLOCK_HIGH) [1]set pins, (SYNC_HIGH + CLOCK_LOW)jmp x-- bit_loop
Register X wird als Schleifenzähler für die innere Schleife benutzt. Der Test am Schleifenende bewirkt, dass sie einmal mehr, also 19-mal durchlaufen wird. Die Schleife für ein Bit benötigt genau 4 Takte:
- Erst SYNC high und CLOCK high plus 1 Wartetakt
- dann SYNC HIGH und CLOCK low: kein Wartetakt, weil noch der Test auf Schleifen-Ende folgt.
set pins, (SYNC_LOW + CLOCK_HIGH) [1]set pins, (SYNC_LOW + CLOCK_LOW)
Nach der Schleife wird noch ein einzelnes Bit mit SYNC LOW für das Parity-Bit ausgegeben.
Auch dieses Bit benötigt 4 Takte: Der 4. Takt wird am Programm-Anfang in 'set x,18' verbraucht.
.wrap
Ende der äußeren Schleife: Die State Machine macht ohne Unterbrechung oben bei '.wrap_target' weiter.
Das PIO-Program für die X und Y Data Lines
Die State Machines für X-DATA und Y-DATA arbeiten das selbe Programm ab, lediglich ihr Side-Setting wurde im C++-Programm auf andere GPIO-Pins gemappt.
Auch diese State Machines laufen mit 8 MHz, haben also pro Bit 4 Takte zur Verfügung.
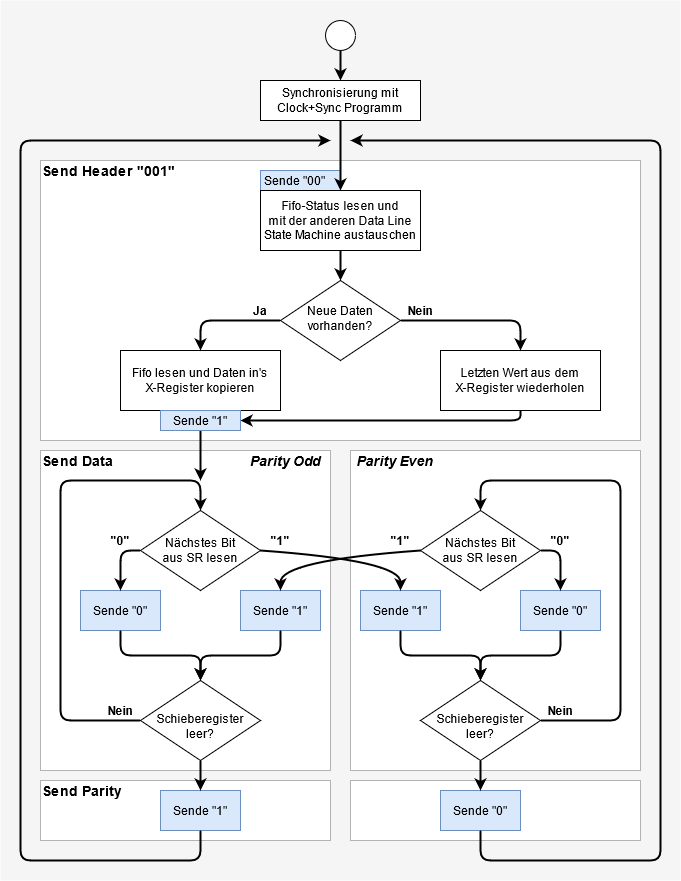
Pro Daten-Frame werden 3 Header-Bits '001', 16 Datenbits und ein Parity-Bit mit gerader Parität gesendet. Während der immer gleiche Header gesendet wird, synchronisieren die beiden State Machines ihre Entscheidung, ob sie das nächste Wort aus der FIFO lesen oder den letzten Wert wiederholen. Während die Datenbits gesendet werden, verzweigt die State Machine ihren Programmfluss nicht nur gemäß der zu sendenden Datenbits sondern auch gemäß der aktuellen Parität. Dem Weg durch die innere Schleife ist also immer ein bestimmter Parity-Zustand zugeordnet.
Das Schleifenende wird daran erkannt, dass das Schieberegister leer ist. Dann wird das jeweilige Parity-Bit ausgegeben. Weil die äußere Schleife so zwei Enden hat, kann 'wrap' nicht sinnvoll verwendet werden. Stattdessen wird ganz konventionell JMP benutzt.
Das Programm am Stück:
.program XY2_100_data
.define public sm_clock 8000000
.side_set 2 opt ; the data+ and data- pins
.define DATA_HIGH 0b01 ; pin N = 1, pin N+1 = !1
.define DATA_LOW 0b10 ; pin N = 0, Pin N+1 = !0
public start:
nop [1] ; start delay to run in sync with the clock SM
next_word:
mov pins, status side DATA_LOW ; set pin from TX fifo status
in null, 31 [1] ; clear isr
in pins, 1 ; read pin back
mov y, isr ; move bit to y for testing
jmp !y, tx_not_empty
tx_empty:
mov osr,x
jmp tx_common
tx_not_empty:
pull block
mov x, osr ; store value for repeating
tx_common:
out null,16 side DATA_HIGH [1] ; discard high bits
; send data bits until OSR empty:
loop_odd:
out y, 1 ; get next data bit
jmp !y, send_0_odd
send_1_odd:
jmp loop_end_even side DATA_HIGH ; send '1' and toggle parity
send_0_odd:
jmp loop_end_odd side DATA_LOW ; send '0' and keep parity
loop_even:
out y, 1 ; get next data bit
jmp !y, send_0_even
send_1_even:
jmp loop_end_odd side DATA_HIGH ; send '1' and toggle parity
send_0_even:
jmp loop_end_even side DATA_LOW ; send '0' and keep parity
loop_end_odd:
jmp !osre, loop_odd
nop [1]
jmp next_word side DATA_HIGH [3] ; send '1' to make parity even
loop_end_even:
jmp !osre, loop_even
nop [1]
jmp next_word side DATA_LOW [3] ; send '0' to keep parity even
Schritt für Schritt:
.side_set 2 opt
Wir benutzen Side-Set um die Data Lines zu setzen. Dadurch können wir den Programmfluss im 'eigentlichen' Code steuern und gleichzeitig die Datenleitungen setzen. Wir haben 2 Pins pro Kanal (DATA+ und DATA-) und wir setzen sie nicht in jedem Opcode, deshalb ist Side-Set in diesem Programm optional.
.define DATA_HIGH 0b01 ; pin N = 1, pin N+1 = !1
.define DATA_LOW 0b10 ; pin N = 0, Pin N+1 = !0
Convenience-Definition der Bitmuster, mit denen die differenziellen Leitungspaare auf '0' oder '1' gesetzt werden.
public start:
Definition eines 'public label' für den Programmstart. Dieses wird als #define XY2_100_data_offset_start exportiert.
nop [1]
next_word:
Der Programmstart muss um zwei Takte verzögert werden, damit wir mit dem Clock+Sync Programm synchron sind. Unser Programm setzt mit Side-Set sofort – am Anfang des Befehls – das neue Bit auf die Datenleitung, während Clock+Sync zwei Takte Vorlauf hat: für 'set x,18' und noch einen, weil das dort verwendete SET erst am Ende des Befehls wirkt.
Danach das Label für den Rücksprung zum Start der äußeren Schleife.
mov pins, status side DATA_LOW
Setze den Fifo-Synchronisierungs-Pin gemäß unseres TX FIFO Status.
Beide State Machines schreiben ihren Status gleichzeitig auf den selben Pin. Dabei 'gewinnt' die State Machine für die Y-Daten, wie oben erklärt.
Per Side-Set wird '0' ausgegeben: Das erste Bit des Headers '001'.
Das Pin-Mapping für OUT und Side-Set und die Bedeutung von 'status' wurde im C++-Programm auf 'TX FIFO Füllstand' konfiguriert.
in null, 31 [1]
in pins, 1
Dann lesen beide State Machines den Zustand dieses Pins wieder ein. Er enthält jetzt, wie oben erklärt, den Status der Y-Data State Machine. Um nur ein einzelnes Bit lesen zu können, benutzen wir dafür das Empfangs-Shiftregister, dessen andere 31 Bits wir zuvor löschen, indem wir sie auslesen. Dabei werden Nullen nachgeladen.
Das Pin-Mapping für IN wurde im C++-Programm konfiguriert.
mov y, isr
jmp !y, tx_not_empty
Danach kopieren wir das erfolgreich vereinzelte Bit in das Y-Register, testen es und verzweigen entsprechend.
tx_empty:
mov osr,x
jmp tx_common
Die TX FIFO von Y-DATA ist leer und wir müssen den letzten Wert aus dem X-Register wiederholen:
Wir laden das OSR (das Output Shiftregister) aus dem X-Register nach und springen zum gemeinsamen Teil.
tx_not_empty:
pull
mov x, osr
Die TX FIFO von Y-DATA enthält Daten:
Wir laden das OSR (das Output Shiftregister) aus der FIFO nach und speichern den Wert für eine eventuelle Wiederholung im X-Register.
tx_common:
out null,16 side DATA_HIGH [1]
Ab hier wieder gemeinsam:
Das XY2-100 Interface sendet das MSB zuerst, wir schieben also nach links. Deshalb werfen wir die oberen 16 Bits des 32 Bit breiten Schieberegisters gleich weg.
Außerdem sind seit Start 8 Takte verstrichen (zählt nach! ![]() ) und wir müssen die Datenleitung für das letzte Bit des '001' Headers auf '1' setzen. Deshalb gibt es jetzt wieder eine Side-Set Anweisung im Befehl.
) und wir müssen die Datenleitung für das letzte Bit des '001' Headers auf '1' setzen. Deshalb gibt es jetzt wieder eine Side-Set Anweisung im Befehl.
Jetzt werden die 16 Datenbits gesendet.
Das Ende der inneren Schleife wird durch Abfrage des TX Shiftregister Status ermittelt.
Es gibt zwei Wege durch die Schleife, die den Status 'Parity Even' und 'Parity Odd' repräsentieren. Am Anfang ist die Parität Odd, weil im Header bereits ein einzelnes gesetztes Bit gesendet wurde. Entsprechend starten wir bei loop_odd.
Parity ist im Moment 'Odd':
loop_odd:
out y, 1
jmp !y, send_0_odd
Lade das nächste Bit aus dem Output Shiftregister nach Y um es dort zu testen.
Wir können das Bit nicht mit 'out pins,1' direkt auf die Datenleitungen ausgeben, weil wir 2 komplementäre Bits ausgeben müssen und dafür Side-Set benutzen. Wir testen also das Bit und verzweigen in den Pfad, der das richtige Side-Set macht und gleichzeitig so den neuen Parity-Status 'speichert'.
send_1_odd: jmp loop_end_even side DATA_HIGH ; send '1' and toggle parity
Sende '1' mittels Side-Set und verzweige in den Programmpfad für Parity 'Even', weil sich die Parität der gesendeten Einsen geändert hat.
send_0_odd: jmp loop_end_odd side DATA_LOW ; send '0' and keep parity
Sende '0' und bleibe im Zweig für Parity 'Odd'.
Das selbe Spiel, aber Parity ist im Moment 'Even':
loop_even: out y, 1 jmp !y, send_0_even send_1_even: jmp loop_end_odd side DATA_HIGH ; send '1' and toggle parity send_0_even: jmp loop_end_even side DATA_LOW ; send '0' and keep parity
Schleifen-End-Tests für Parity 'odd':
loop_end_odd:
jmp !osre, loop_odd
Ende der inneren Schleife:
Wir prüfen mit einem bedingten Sprung, ob das Output Shiftregister leer ("empty") ist: "!osre". Wenn nicht, springen wir zum Schleifenstart für ungerade Parität zurück.
nop [1] jmp next_word side DATA_HIGH [3] ; send '1' to make parity even
Alle Datenbits sind übertragen:
Wir senden als Paritätsbit eine '1', um gerade Parität herzustellen.
Zuerst müssen wir noch 2 Takte warten, weil seit dem Side-Set des letzten Datenbits erst 2 Takte vergangen sind. Dafür muss ausnahmsweise, weil sonst nichts zu tun ist, ein NOP herhalten.
Das Paritätsbit wird insgesamt 4 Takte lang ausgeben, dann erfolgt der Neustart der äußeren Schleife. ![]()
Schleifen-End-Tests für Parity 'even':
loop_end_even: jmp !osre, loop_even nop [1] jmp next_word side DATA_LOW [3] ; send '0' to keep parity even
Das selbe Spiel, jetzt aber bei gerader Parität:
Wir prüfen, ob das Output Shiftregister noch Daten enthält und springen dann zum Schleifenstart für gerade Parität zurück.
Sonst senden wir als Paritätsbit eine '0', um die gerade Parität zu erhalten.
Das Paritätsbit wird insgesamt 4 Takte lang ausgeben, dann erfolgt der Neustart der äußeren Schleife.
![]()
Vorschau
In Kürze erscheint noch ein dritter Artikel, in dem ich auf Anwendungsmöglichkeiten der Interpolier-Einheiten des RP2040 eingehen werden.
Über den Autor
Günter Woigk arbeitet bei der Mathema GmbH im Bereich Embedded als Software Developer mit dem Schwerpunkt auf C und C++ Programmierung. Momentan interessiert er sich für die Möglichkeiten, die der neue Ansatz im RP2040 für kommerzielle Entwicklungen bietet.
Links
- https://www.raspberrypi.org/products/raspberry-pi-pico/
- rp2040 datasheet.pdf
- raspberry-pi-pico-c-sdk.pdf
Sourcen
Die Programme in diesem Artikel sind Copyright (c) MATHEMA GmbH und werden unter der BSD-3-Clause Lizenz zur Verfügung gestellt.
Video
Quellenangaben
- Das Bild vom Raspi Pico ist cc-by-sa (c) Günter Woigk 2021.
- Die Grafiken zum Daten- und zum Programmfluss sind cc-by-sa (c) Günter Woigk, Mathema GmbH.
- Die vom Laser gezeichneten Bilder sind gemeinfrei.
- Das Bild zur Registerübersicht einer PIO State Machine stammt aus dem RP2040 Datasheet auf raspberrypi.org





